Learning Robust Multimodal Knowledge Graph Representations
Abstract
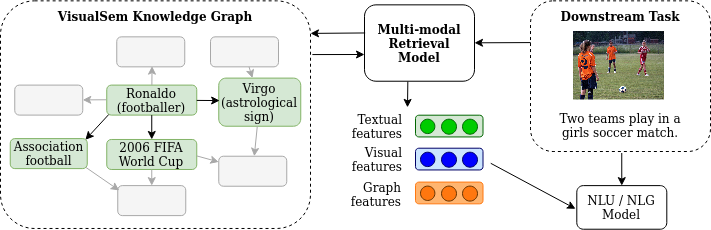
We propose a new method to make natural language understanding models more parameter efficient by storing knowledge in an external knowledge graph (KG) and retrieving from this KG using a dense index. Given some task data, e.g., sentences in German, we retrieve entities from the KG and use their multimodal representations to improve downstream task performance. Using VisualSem as our KG, we compare a mix of tuple-based and graph-based algorithms to learn robust representations of entities that are grounded on their multimodal information. We then demonstrate the usefulness of our learned entity representations on two downstream tasks. Using our best learned representations, we improve performance on the multilingual named entity recognition (NER) task by 0.3%-0.7% (F1 score), while on the visual sense disambiguation task, we achieve up to 3% improvement in accuracy in the low-resource setting.
Ningyuan (Teresa) Huang
Flatiron Research Fellow
I am a Flatiron Research Fellow at Flatiron Institute.